Introduction
As data sources grow even early-stage, pre-commercialization healthcare organizations need to adopt data stores, lakes and warehouses to enable an analysis of prescription, and claims trends, estimate market sizes, develop go-to-market strategies and construct target lists. In such organizations, the data environment is chaotic, with constant change occurring in commercial data options, ad hoc data purchases, supplementary indirect data, etc. As commercialization approaches and progresses, the chaos settles, but the volumes of data and sources explode, with activity, sample requests, quick starts, and patient assistance programmes all coming into play. Hence having a data lake solution that can quickly integrate new data sources, store, cleanse and quality-check incoming data in a configurable manner can make the difference between smooth commercialization and chaos.
What’s a data lake?
Data lakes are a more modern evolution of the data warehouse concept. The key difference between warehouses and lakes is that data lakes store more data in the raw and unprocessed form rather than modify incoming data to minimize redundancy and have a single global schema for all data across the organization. This evolution occurred from the explosion of cheap storage and computing power, the demand of more data across all organizational functions at the more granular level as well as the general explosion in volumes of data.
What can we use to build a data lake?
Primarily to construct a data lake, we require storage to store data, and some computing required to process, aggregate, filter, query and cleanse data in a logical fashion. Storage includes storage for raw data that has been ‘ingested’ into the data lake and storage for aggregated/analyzed outputs for analysis, training ML/AI models, etc. The raw data storage should be as cheap as possible since we need bulk loads of it in a data lake. The compute should be scalable to react to peaks and troughs in data throughput rates efficiently and not ‘waste’ compute resources.
For raw data storage, Amazon S3 is an ideal solution. Storage is cheap and reliable.
For the storage of aggregated data and output of the analysis, Redshift is efficient. It can store petabyte-level data, querying is parallelizable by a large number of nodes in a cluster. Plus, Amazon Spectrum and Athena allow you to expose flat files in S3 as tables in an external schema in Redshift.
For computing, Amazon Lambda functions are ideal for scalable processing that can be massively parallelized and invoked on a needs basis
As a result, all of the components required to construct a data lake are available in the AWS ecosystem.
What are these components?
Amazon Simple Storage Service (Amazon S3) is a file storage service that offers inexpensive storage but high levels of security, reliability and availability.
Amazon Redshift is a petabyte-scale data warehouse that allows parallel query execution through their cluster nodes.
Amazon Athena is a service that allows you to query data that is stored in S3 in flat files, comma-separated, positional, and parquet formats through a simple SQL like interface. It allows for large datasets to be accessed through a pay per query scan model.
Amazon Redshift Spectrum is a service that allows for data stored in S3 flat files, comma-separated, positional, and parquet formats to be exposed as read-only external schemas in Redshift. Querying these files is as easy as querying any table in Redshift, and this data doesn’t occupy any space on the Redshift cluster itself.
AWS Lambda is a serverless computing service that lets you run code without provisioning or managing servers. This allows you to invoke functions and compute on demand without having to maintain running servers during lean data periods.
How can we make these things work together as a Data Lake?
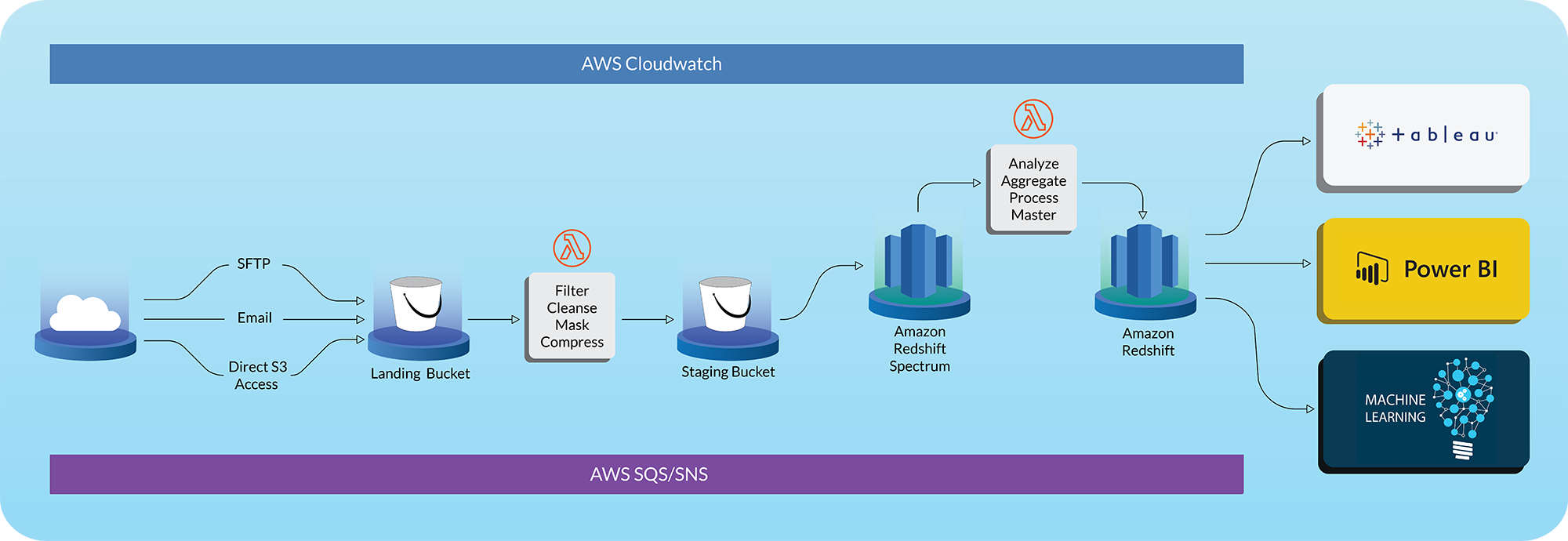
The data flow diagram explains the high level architecture of such a data lake. It basically follows the following steps:
1. Incoming data is landed into a landing area in S3
2. A lambda function then cleanses, filters and performs any data quality checks on the file before moving it to the staging area in a logically named folder and file location. Any masking/privacy specific processing may also be performed in this step. Optionally a conversion to columnar data storage and compression may also be undertaken to improve Athena/Spectrum performance and reduce costs
3. Amazon Glue (a data cataloguing service) auto senses the new file in the staging area
4. AWS Lambda functions run analytical SQL queries/python scripts/pipelines to read data from the AWS Spectrum external schema tables, process, aggregate, analyze and model them and store output in Redshift Tables. In case you want to master a few dimensions or map values between data sources, you can leverage such lambda functions to perform such actions as well
5. End Users have access to the raw tables through external schema tables, access calculated outputs in the Redshift tables, or create their own views on top of the raw tables and access them later
6. Downstream systems can access Redshift to create Business Intelligence dashboards, update machine learning models or create specific feeds to ingest processed data
7. All of these components can be orchestrated using AWS SQS or AWS SNS to trigger various components. Also, AWS Cloudwatch allows for logging, monitoring and scheduling periodic updates
Conclusions and Benefits
Overall, the AWS ecosystem provides a wide variety of services and tools to build a data lake or data warehouse that works for your organizational needs. They only need to be stitched together using expertise and experience in these services. The above framework allows clients to deploy a near real time data lake where data is available to query within minutes of having arrived in the landing area. Despite such performance, costs can be kept low by using an architecture that scales with your data and uses.
Aurochs Solutions has expertise in deploying data lakes using component services in AWS and can use the same techniques to deploy various enterprise systems. We also have strong UI/UX capabilities to create dashboards, operational monitoring UIs, and data steward interfaces that can sit on top of these frameworks for stakeholder access.
Feel free to reach out to us at sujeet.pillai@aurochssoftware.com in case you have any questions or to talk about your current challenges and bounce off any ideas with no strings attached.
